A Full-Stack Voice AI Platform with TTS, Voice Conversion, and Generative Audio
Client
Personal
Timeframe
March 30 - May 12
Stack
PyTorch, FastAPI, Docker, StyleTTS2, Seed-VC, Make-An-Audio, React, Next.js, Tailwind CSS, AWS, Inngest, Auth.js
Project Overview
The goal was to create a full-stack, self-hosted alternative to ElevenLabs—a platform capable of Text-to-Speech (TTS), Voice Conversion, and Text-to-Audio generation—using open-source AI models. The motivation stemmed from the limitations of proprietary tools like ElevenLabs (e.g., closed APIs, high costs). This project successfully delivered a modular, scalable voice AI platform that brings powerful generative audio capabilities to users without vendor lock-in.
Implemented Features
The final platform includes the following components:
- Text-to-Speech (TTS) with StyleTTS2 for high-quality, expressive voice generation.
- Voice Conversion using Seed-VC, allowing identity-preserving voice transformations.
- Text-to-Audio generation powered by Make-An-Audio, enabling non-speech soundscape creation.
- Custom voice fine-tuning from just a few minutes of user-provided audio samples.
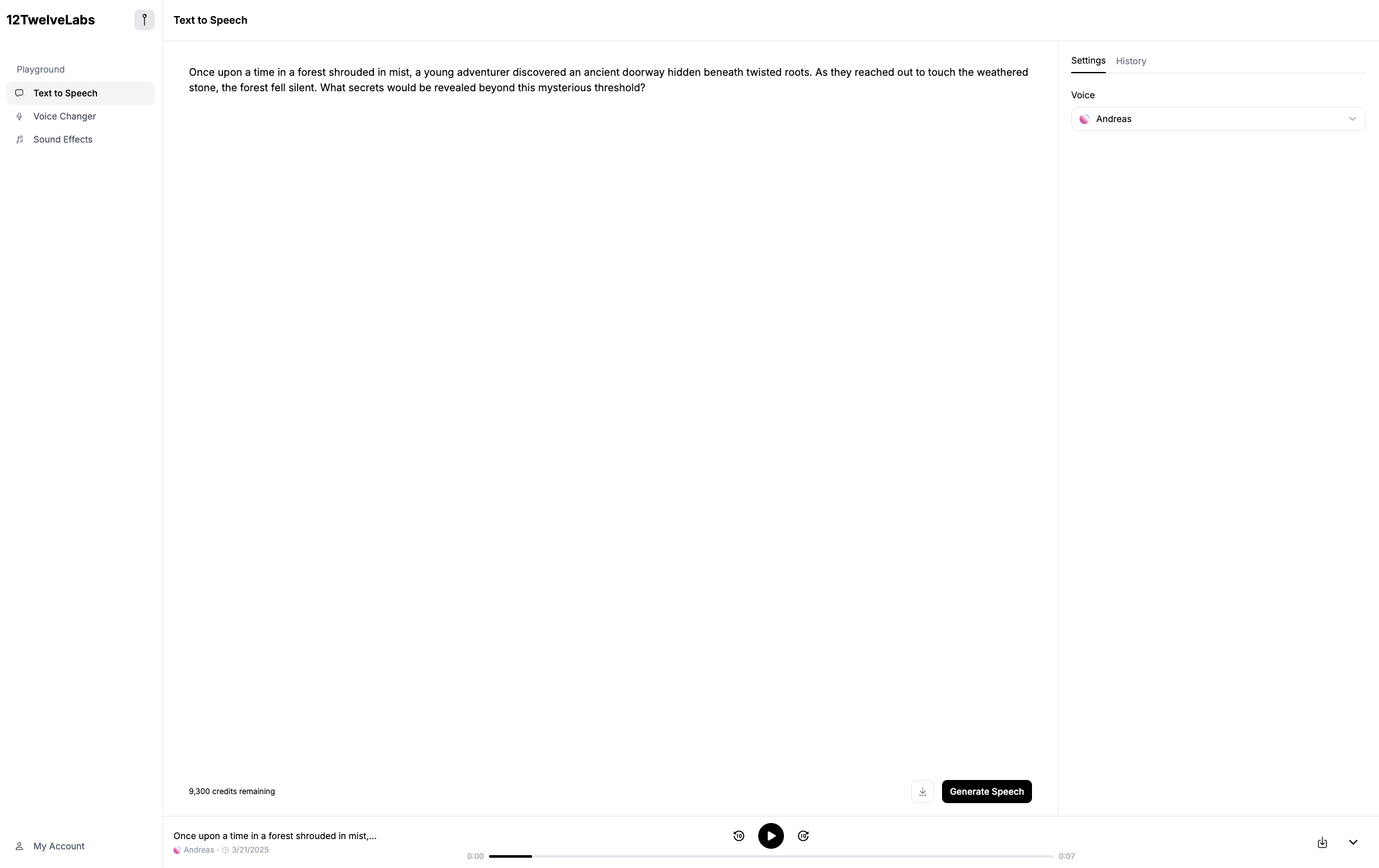
- A modern, credit-based web interface for managing usage and output
A modern web interface with:
- Real-time voice switching
- Custom voice uploads
- Audio history and downloads
- A credit-based system to track and manage usage
Technical Stack
AI/Deep Learning Models
- StyleTTS2 – Diffusion-based TTS with strong expressiveness and naturalness
- Seed-VC – Neural voice conversion with clear speaker identity preservation
- Make-An-Audio – Latent diffusion-based text-to-audio synthesis engine
Backend & Infrastructure
- PyTorch for training, inference, and fine-tuning pipelines
- FastAPI serving RESTful endpoints
- Inngest for GPU queue management to ensure efficient task execution
- Docker for model containerization and deployment
- AWS S3 used for storing generated audio files
Frontend
- Built using Next.js 15.3.0, React, Tailwind CSS
- Auth.js for user authentication; optional integration with Clerk
- Clean, modular UI designed for smooth UX
Research & Innovation Highlights
While the models are open-source, this project goes beyond simply running them:
- Fine-tuned user voices with just 2–5 minutes of training data
- Benchmarked audio quality and latency across models to inform trade-offs
- Built a hybrid inference pipeline: Seed-VC ➜ Make-An-Audio to combine voice conversion with generative audio
- Identified and mitigated bottlenecks related to memory consumption and model size (especially with diffusion models)
- Designed the system with future SaaS scalability in mind
Outcome & Impact
This project demonstrates a complete full-stack solution that integrates advanced generative AI, infrastructure engineering, and user experience design. It offers the same core functionalities as ElevenLabs but remains open, customizable, and cost-efficient. The system is already usable in production scenarios like:
- Custom voice assistants
- Content creation workflows
- Game and virtual world audio
- Accessibility enhancements
This build showcases technical mastery in diffusion models, transformers, real-time inference systems, and product-ready AI engineering.